





Introduction
One common task when working with large datasets is the need to generate unique identifiers for each record. In this tutorial, we will explore how to easily add an ID column to a Pandas DataFrame. In order to do this, we use the index attribute of a Pandas DataFrame.
Why Generate an ID Column?
Generating an ID column serves various purposes in data analysis and processing. It facilitates tasks such as indexing, merging datasets, and tracking individual records. By assigning unique identifiers to each row, users can streamline data manipulation operations and gain insights from structured datasets more effectively.
Import Libraries
First, we import the following python modules:
import pandas as pdCreate Pandas DataFrame
Next, we create a Pandas DataFrame with some example data from a dictionary:
data = {
"language": ["Python", "Python", "Java", "JavaScript"],
"framework": ["Django", "FastAPI", "Spring", "ReactJS"],
"users": [20000, 9000, 7000, 5000]
}
df = pd.DataFrame(data)
df
Generate ID Column
Pandas provides several approaches to generate unique identifiers. One simple method involves utilizing the index attribute of the DataFrame, which inherently provides a unique label for each row.
In the following, we add a new column named "id" containing unique identifiers based on the DataFrame index:
df["id"] = df.index
df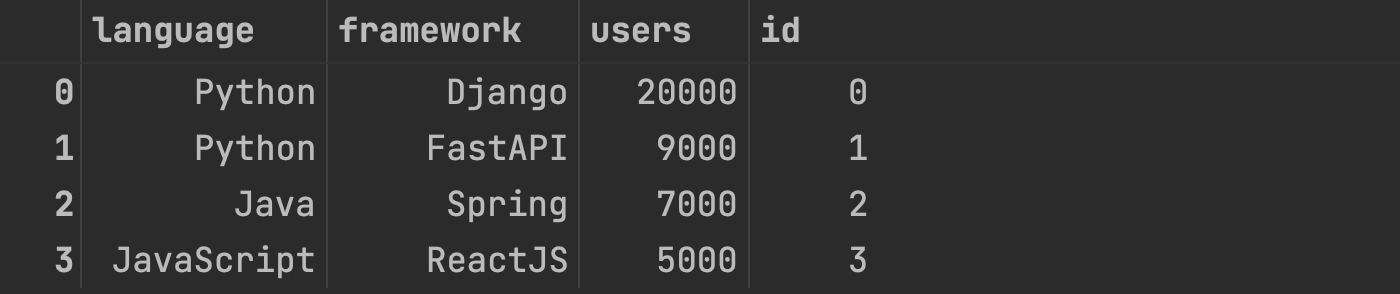
Conclusion
Congratulations! Now you are one step closer to become an AI Expert. In this tutorial, we explored how Pandas simplifies the process of generating an ID column for your datasets. A straightforward and efficient way to add unique identifiers is to use the index attribute of a Pandas DataFrame. Try it yourself!
Also check out our Instagram page. We appreciate your like or comment. Feel free to share this post with your friends.




