





Introduction
In this tutorial, we want to drop duplicates from a Pandas DataFrame. In order to do this, we use the the drop_duplicates() method of Pandas.
Import Libraries
First, we import the following python modules:
import numpy as np
import pandas as pdCreate Pandas DataFrame
Next, we create a Pandas DataFrame with some example data from a dictionary:
mydict = {
"column1": [3, 7, 7, 8, np.nan],
"column2": [11.3, 12.5, 12.5, 0.77, 9.4],
"column3": ["AI", "Python", "Python", np.nan, "AI"],
}
df = pd.DataFrame(mydict)
df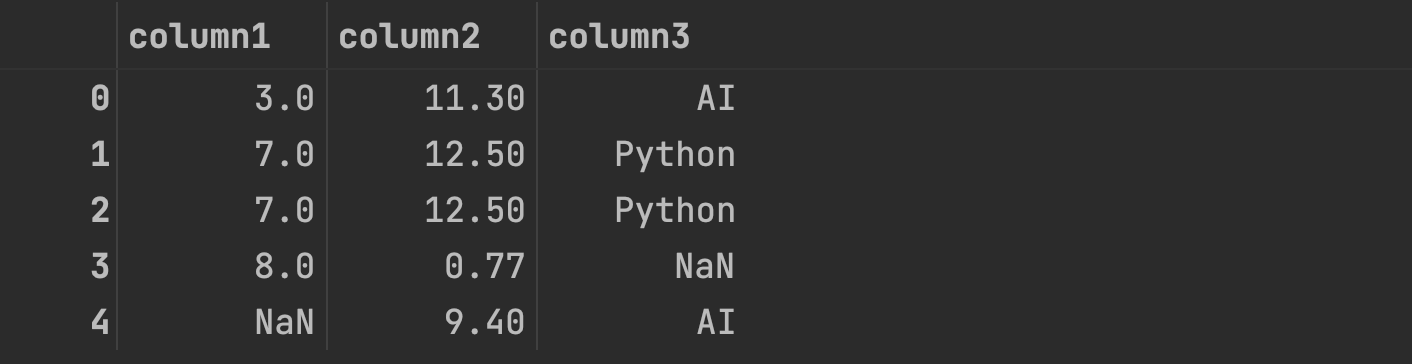
Remove duplicate Rows
Keep First Occurences
Now, we would like to remove duplicate rows from the DataFrame based on all columns. The first occurrences should be kept.
To do this, we use the drop_duplicates() method of Pandas and set the parameter "keep" to "first":
df_cleaned = df.drop_duplicates(keep='first')
df_cleaned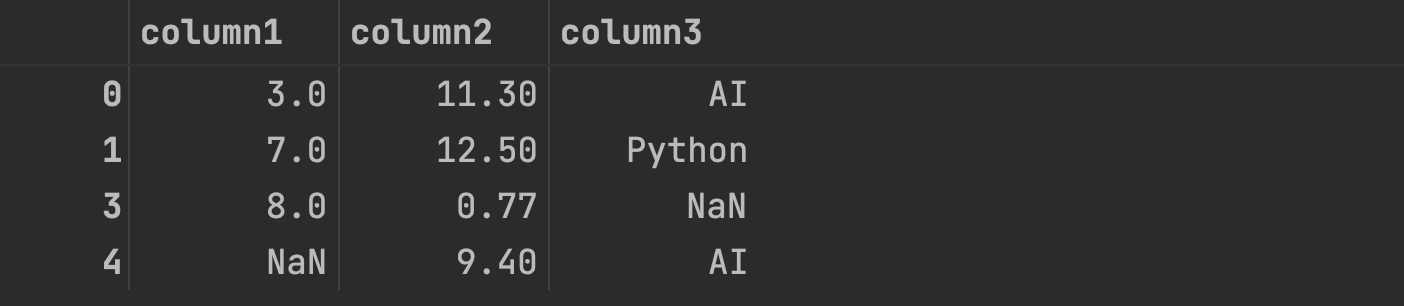
Keep Last Occurences
If we want to keep the last occurrences, we have to set the parameter "keep" to "last":
df_cleaned = df.drop_duplicates(keep='last')
df_cleaned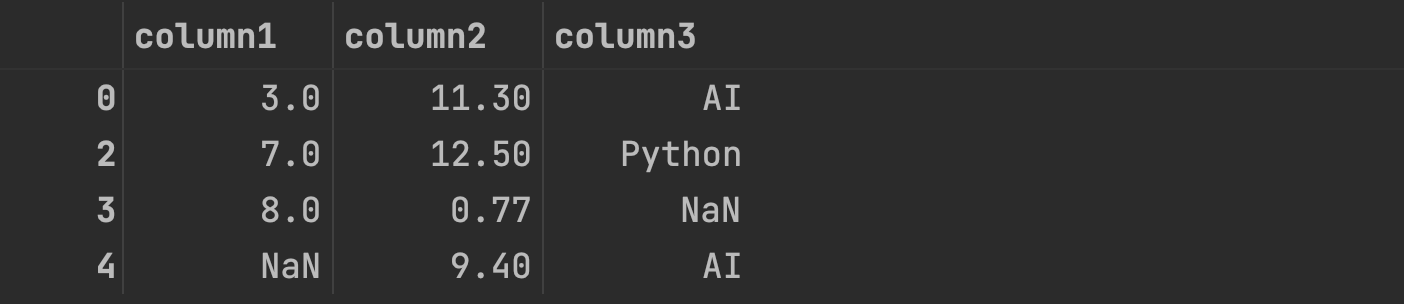
Remove duplicate Rows based on a certain Column
Next, we would like to remove duplicate rows from the DataFrame based on the column "language". The first occurrences should be kept.
To do this, we use the drop_duplicates() method of Pandas with the parameters "keep" and "subset":
df_cleaned = df.drop_duplicates(keep='first', subset=['column3'])
df_cleaned
Conclusion
Congratulations! Now you are one step closer to become an AI Expert. You have seen that it is very easy to drop duplicates from a Pandas DataFrame. We can simply use the drop_duplicates() method of Pandas. Try it yourself!
Also check out our Instagram page. We appreciate your like or comment. Feel free to share this post with your friends.




