





Introduction
In this tutorial, we want to split data into train and test sets. In order to do this, we use the train_test_split() function of Scikit-Learn.
Import Libraries
First, we import the following python modules:
import pandas as pd
from sklearn.model_selection import train_test_splitLoad Data
Now, we load our dataset from a csv file. In order to do this, we use the read_csv() function of Pandas.
The dataset consists of 10 examples with the feature "height" (in cm) and the target variable "weight" (in kg). We save the data in a DataFrame.
dataset = pd.read_csv("data.csv", sep=";")
dataset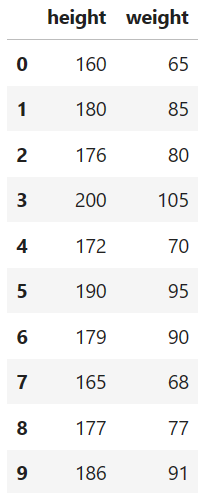
Split Dataset
Now, we would like to split the dataset into a train set and test set. The data should be divided as follows:
- Training: 80%
- Testing: 20%
Besides, we want to shuffle our dataset before applying the split. To do this, we use the function train_test_split() of Scikit-Learn with the following arguments:
X = dataset["height"]
y = dataset["weight"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size = 0.8, shuffle=True)Train and Test Sets
Let's have a look to our two datasets.
Train Set
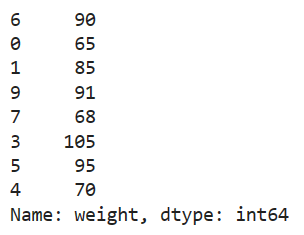
The train set consists of 8 examples and looks as follows:
print(X_train)
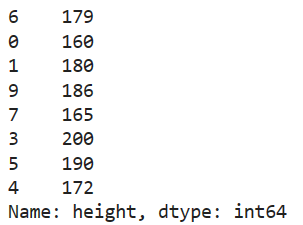
print(y_train)
Test Set
The test set consists of 2 examples and looks as follows:
print(X_test)
print(y_test)

Conclusion
Congratulations! Now you are one step closer to become an AI Expert. You have seen that it is very easy to split data into train and test sets. We can simply use the train_test_split() function of Scikit-Learn. Try it yourself!
Also check out our Instagram page. We appreciate your like or comment. Feel free to share this post with your friends.
